Detecting Manual AWS Actions: An Update!
Feb 18th, 2024 | 9 minute readBack in 2019 I published Detecting Manual AWS Console Actions, which continues to be one of the more popular articles on this blog. In this post I’ll do a refresh with what’s changed in my approach over the last 5 years.
The primary 3 updates are:
Note that this post assumes you have context from the prior post, so if you haven’t read that then I recommend at least giving it a skim first. The premise is how to detect when employees do something in your AWS account outside of an approved infrastructure-as-code workflow.
A new trigger mechanism
In the original post I spent a lot of time and energy trying to capture various user-agent combinations to detect console actions. This was misguided for several reasons:
1) It was a manual and error-prone process. It would never capture all user-agent combinations from the AWS Console, nor would it keep up with new changes over time
2) I was only capturing user-agents from the AWS Console and not from the aws-cli or other api clients. The term “Console” actions is a misnomer - what I really care about are “Manual” actions from employees, whether they’re through the console or through the api
The approach we take at my current employer is instead the following:
The only way that employees can access AWS is through Okta /
AssumeRoleWithSAML. There are no other mechanisms for an employee to get access to AWS (zero IAM users, etc)When someone assumes an employee role, Okta is configured to set the AWS role session name to be the employee email address
The above two conditions are an invariant for employee access to AWS. And to detect when an employee performs a manual AWS action we simply check each Cloudtrail event for:
- the role session name ends with
@employer.com, and - the event has the
readOnlyflag set to false and isn’t further filtered out below
This solves both problems above - console and api actions are both alerted on and it covers 100% of manual actions / there’s no possibility of some missing actions. Here’s a screenshot of what our alerts look like now:
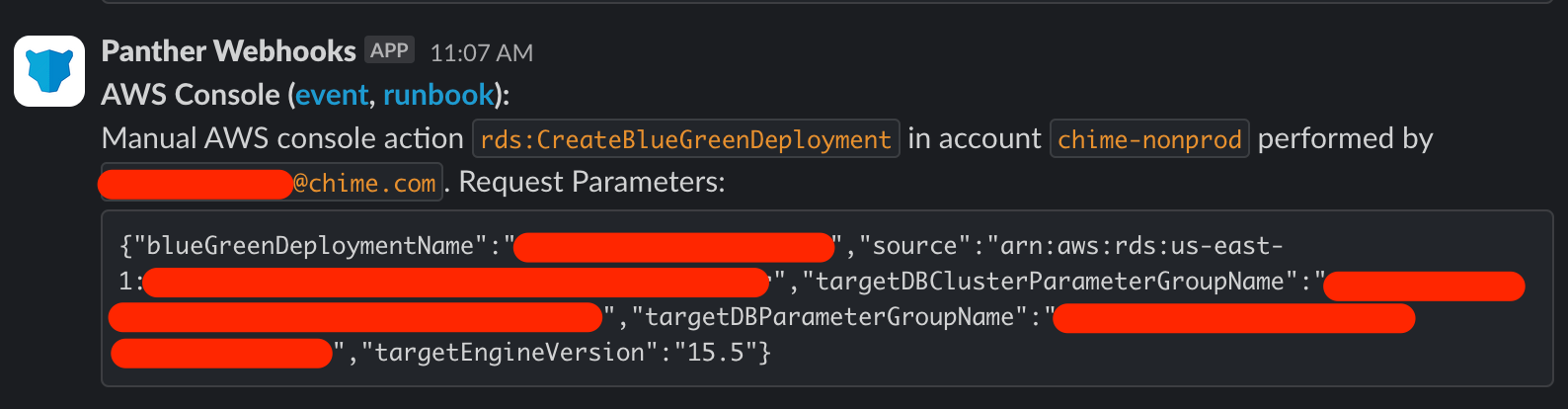
An updated list of filtered IAM actions
As mentioned above I’m really only interested in mutating AWS actions, so in the original post I was filtering out read-only events by checking the event name for some prefixes like List, Get, and Describe, along with a few specific event names to not alert on. The 2nd post update is that I now rely on the Cloudtrail readOnly flag instead, which tells us whether the event was mutating or not.
This works mostly ok, except AWS has a number of events that are incorrectly tagged as being mutating events. To get around this, we filter out the following hardcoded list of actions in our alerting (note: some of these are genuinely not read-only and are filtered out for other reasons - see below):
"access-analyzer:StartPolicyGeneration",
"airflow:CreateWebLoginToken",
"ecr:BatchGetRepositoryScanningConfiguration",
"bedrock:GetFoundationModelAvailability",
"bedrock:ListFoundationModelAgreementOffers",
"billingconsole:AWSPaymentPortalService.DescribePaymentsDashboard",
"billingconsole:AWSPaymentPortalService.GetAccountPreferences",
"billingconsole:AWSPaymentPortalService.GetPaymentsDue",
"billingconsole:AWSPaymentPreferenceGateway.Get",
"billingconsole:FindPaymentInstruments",
"billingconsole:GetAllowedPaymentMethods",
"billingconsole:GetBillingNotifications",
"billingconsole:GetPaymentInstrument",
"billingconsole:GetPaymentPreference",
"billingconsole:GetTaxInvoicesMetadata",
"billingconsole:ListCostAllocationTags",
"ce:CreateReport",
"ce:ListCostAllocationTags",
"ce:StartSavingsPlansPurchaseRecommendationGeneration",
"cloudwatch:TestEventPattern",
"cloudwatch:TestMetricFilter",
"cloudwatch:TestScheduleExpression",
"config:SelectAggregateResourceConfig",
"config:SelectResourceConfig",
"dms:RefreshSchemas",
"dms:StartReplicationTask",
"dms:StopReplicationTask",
"dms:TestConnection",
"dynamodb:DescribeContributorInsights",
"dynamodb:DescribeExport",
"dynamodb:DescribeImport",
"dynamodb:DescribeKinesisStreamingDestination",
"dynamodb:ListContributorInsights",
"dynamodb:ListExports",
"dynamodb:ListImports",
"ec2:SearchTransitGatewayRoutes",
"ecr:CompleteLayerUpload", # We get the PutImage event at the end of an upload
"ecr:DescribeRepositoryCreationTemplates",
"ecr:InitiateLayerUpload", # We get the PutImage event at the end of an upload
"ecr:UploadLayerPart", # We get the PutImage event at the end of an upload
"eks:ListInsights",
"events:DescribeEndpoint",
"glue:BatchGetCrawlers",
"glue:BatchGetJobs",
"glue:BatchGetTriggers",
"glue:BatchStopJobRun",
"glue:CancelStatement",
"glue:CreateSession",
"glue:ListCustomEntityTypes",
"glue:RunStatement",
"glue:StartJobRun",
"glue:StopSession",
"guardduty:DescribeMalwareScans",
"guardduty:GetRemainingFreeTrialDays",
"iam:GenerateOrganizationsAccessReport",
"iam:GenerateServiceLastAccessedDetails",
"inspector2:CreateFindingsReport",
"kinesisanalytics:CreateApplicationPresignedUrl",
"lambda:Invoke",
"logs:StartLiveTail",
"logs:StartQuery",
"logs:StopLiveTail",
"logs:StopQuery",
"networkmanager-chat:CreateConversation", # Using Amazon Q
"networkmanager-chat:SendConversationMessage", # Using Amazon Q
"networkmanager:GetConnectPeerAssociations",
"pipes:ListPipes",
"s3:CompleteLayerUpload",
"s3:CompleteMultipartUpload",
"s3:CopyObject",
"s3:CreateMultipartUpload",
"s3:DeleteObject",
"s3:DeleteObjects",
"s3:GetObject",
"s3:InitiateLayerUpload",
"s3:PutObject",
"s3:UploadPart",
"s3:UploadPartCopy",
"sagemaker:StartPipelineExecution",
"sagemaker:StopPipelineExecution",
"secretsmanager:ReplicateSecretToRegions",
"securityhub:GetUsage",
"signin:ConsoleLogin",
"signin:GetSigninToken",
"signin:SwitchRole",
"signin:UserAuthentication",
"sso-directory:SearchGroups",
"sso-directory:SearchUsers",
"sso:Authenticate",
"sso:Federate",
"sso:Logout",
"sts:AssumeRole",
"support:AddAttachmentsToSet",
"support:AddCommunicationToCase",
"support:CreateCase",
"support:ResolveCase",
"transcribe:StartTranscriptionJob",
"trustedadvisor:CreateExcelReport",
"trustedadvisor:DescribeAccount",
"trustedadvisor:DescribeAccountAccess",
"trustedadvisor:DescribeCheckItems",
"trustedadvisor:DescribeCheckRefreshStatuses",
"trustedadvisor:DescribeChecks",
"trustedadvisor:DescribeCheckSummaries",
"trustedadvisor:DescribeOrganization",
"trustedadvisor:DescribeReports",
"trustedadvisor:DescribeRisk",
"trustedadvisor:DescribeRiskResources",
"trustedadvisor:DescribeRisks",
"trustedadvisor:GetExcelReport",
"trustedadvisor:RefreshCheck",
A few things to note about this list:
- It’s driven by the set of services we use, so it may not be exhaustive, but you get the idea
- Some of these events may be interesting their own right. For instance
signin:ConsoleLogin,airflow:CreateWebLoginToken,sts:AssumeRole, etc - it’s debatable whether or not these constitute a “read-only” event and you may want to create dedicated alerting on them - Some events definitely are mutating but we simply don’t care about them because they’re operational (so they couldn’t go into our terraform setup anyway, like
support:CreateCase) or simply common enough for a subset of our employees that they’re not worth alerting on (likeglue:StartJobRun)
I’d encourage you to go through the list line by line and use what makes sense for your environment.
Detecting session name bypasses
The 3rd and final update is that the new trigger mechanism (checking that the role session name on the Cloudtrail event ends in @employer.com) has a nuance: some employee roles have permission to assume other roles, which allows changing their session name. For instance we have a team that owns/operates our AWS accounts and it’s normal behavior for them to assume an admin role in the account as part of their day-to-day operations. However in addition to letting them perform maintenance, the nature of the admin role is it can also assume any other role in the account. Also until very recently roles implicitly trusted themselves from a role trust policy perspective (so if they had identity-based permissions to assume themselves, they could do so without an explicit grant in their trust policy, or vice versa), which similarly allowed some roles to change their own role session name.
This creates a detection bypass for us, because someone can sign in through Okta to some initial role, and then perform an sts:AssumeRole call on another role (perhaps the same one) but with a role session name of their choosing - they can drop the email from their existing session name and then none of their actions will trigger an alert. Of course we’ll still have all the Cloudtrail events in our SIEM and it will always be possible to reconstruct precisely what they did in some future investigation if we had to, but we would no longer receive proactive alerts and we might simply miss the event.
To prevent this we created a second alert which triggers on calls to AssumeRole where the original session name ended in @employer.com and the new session name is not identical to the original. The alert looks like this:
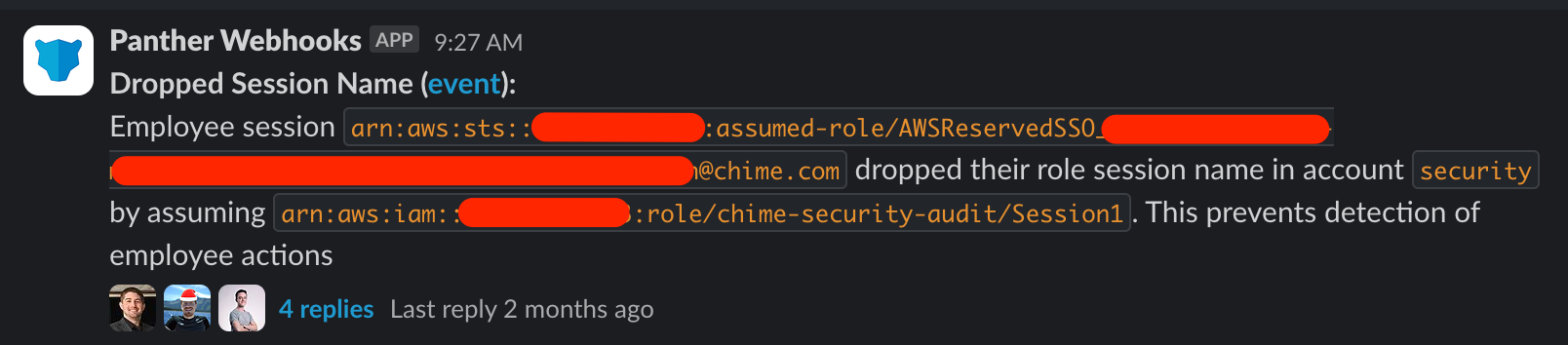
Conclusion
Detecting on manual actions continues to be one of my biggest “bang for your buck” alerts at every employer I’ve worked at - it’s a fanastic tool to enforce that infrastructure changes can only happen via pull requests against your infrastructure-as-code github repo (terraform in our case).
Zooming out from this specific alert - sometimes you’ll find yourself in a position where it’s very hard or impractical or you simply don’t have the data to prevent/detect something bad that you don’t want to happen in your environment. For cases like these it’s incredibly powerful to create invariants (like “employee actions always have a role session name set to their email”), but that can require changing usage patterns and workflows across the company which can be difficult or face internal opposition. Don’t be afraid to change those patterns - creating strong security controls precisely requires being an active participant in your engineering organization and changing usage patterns; not being passive and writing only the alerts that happen to be possible in today’s world. We’re going through a similar exercise now with our Snowflake environment - Snowflake IAM/RBAC is primitive compared to AWS, and rather than accepting that we can’t alert on the Snowflake events we want, we’re enforcing new patterns across the entire company on how to use Snowflake. More on that in a future post 🙂.
P.S. If you enjoy this kind of content feel free to follow me on Twitter: @arkadiyt